Are closed embedding APIs worth paying for in Portuguese?
The top of the MTEB-PT leaderboard is a closed API. Google’s Gemini-Embedding-001 posts the highest 16-task mean, $0.744$, ahead of OpenAI, Voyage, Cohere, Mistral, and Amazon. So the deployment question looks settled: pay for the best. It isn’t, and the reason is the shape of the cost–quality frontier.
Eight of our 54 models are closed commercial APIs, each publishing a single per-million-token list price. We place all eight, plus the open-weight-but-priced Perplexity model, on a single frontier of price against quality.
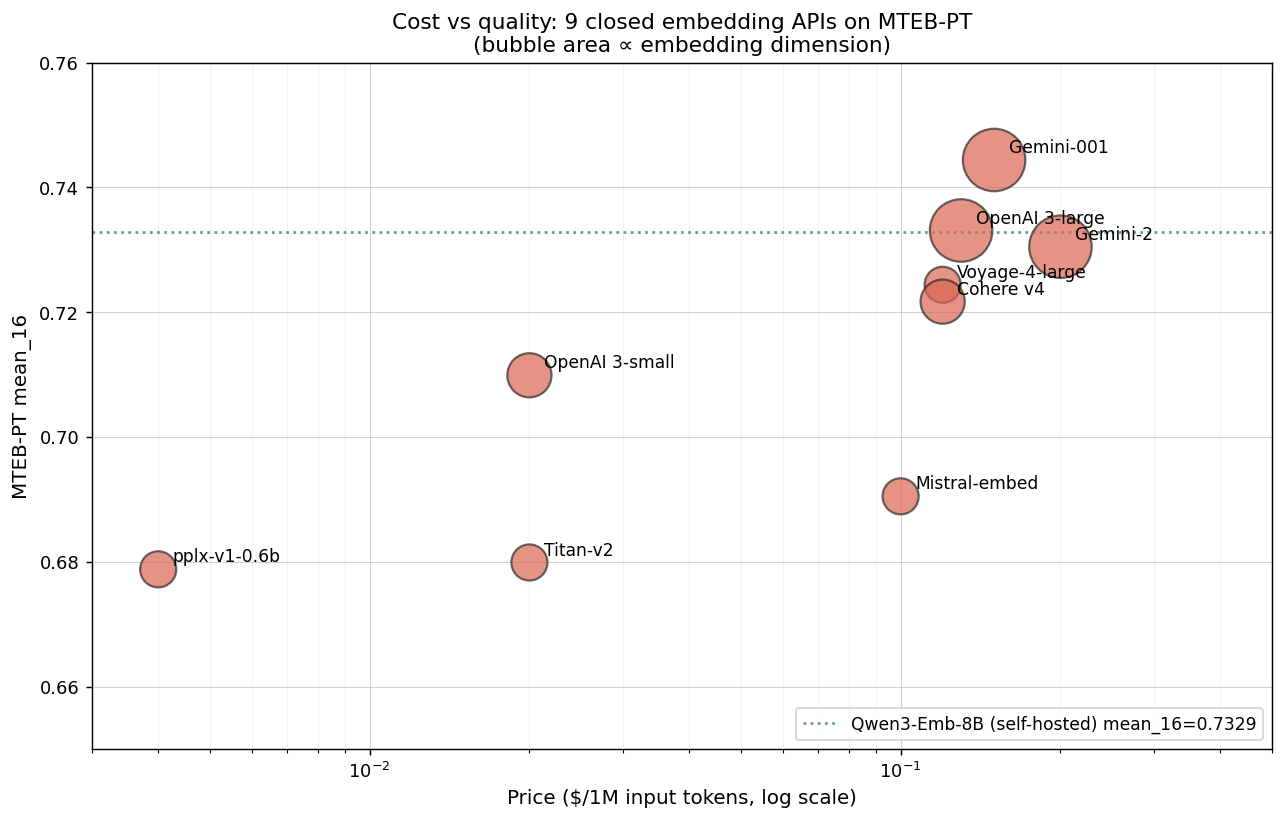
Five of nine are Pareto-optimal
Reading the frontier from cheap to expensive, five endpoints are not dominated by any other:
| Endpoint | Price / 1M | 16-task mean |
|---|---|---|
| Perplexity pplx-embed-v1-0.6b | $0.004 | 0.679 |
| OpenAI text-embedding-3-small | $0.02 | 0.710 |
| Voyage-4-large | $0.12 | 0.724 |
| OpenAI text-embedding-3-large | $0.13 | 0.733 |
| Gemini-Embedding-001 | $0.15 | 0.744 |
The other four priced endpoints are dominated: some cheaper model scores at least as well.
The frontier is shallow
Here is the part that should change the decision. Going from the cheapest endpoint to the best is a 37× increase in price for a gain of just $0.066$ in the 16-task mean. And $0.066$ is only about three times the width of the statistical-tie band on this benchmark, the range within which paired-bootstrap tests cannot tell two models apart.
The effect is even starker inside a single vendor, where only model scale changes. OpenAI’s text-embedding-3-large costs 6.5× its small sibling and returns $0.023$ (entirely inside the tie band) with the small improvement concentrated in retrieval. You are paying a multiple of the price for a difference the benchmark classifies as noise.
And a free model ties the leader
The closed leaders are not even uniquely good. Where self-hosting is acceptable, the open-weight Qwen3-Embedding-8B (Apache 2.0) is statistically tied with the top closed APIs on the 16-task mean, at zero per-token cost. It trades a per-call fee for self-hosting infrastructure, which is an operations question, not an accuracy one.
How to actually choose
Put together, the picture is clear: on native Brazilian Portuguese, the closed APIs are clustered tightly in quality, the price spread between them is large, and an open model reaches the same tier for free. So the right way to read this frontier is in tiers, not ranks. Pick a cost tier you can afford, and within it decide on the things the leaderboard does not measure:
- Latency and throughput: round-trip time, rate limits, batch support.
- Context length: how long your documents are.
- Region and data residency: where the data is allowed to go.
- License and self-hosting: whether an open-weight model removes the per-token fee entirely.
The leaderboard tells you which models are in contention. For Portuguese, that set is wider, and cheaper, than the top rank suggests. Explore it on the live leaderboard.